
Software Engineer Intern
May 2020 - January 2021 | Remote
From May 2020 to January 2021, I worked as a software engineer intern at Sourcegraph on the Distribution team. The Distribution team is responsible for making Sourcegraph easy to deploy, scale, monitor, and debug. The team also solves challenging problems that our customers face when they deploy and scale Sourcegraph on-premise in a variety of environments, and that Sourcegraph faces when we deploy and scale Sourcegraph Cloud (the largest Sourcegraph installation in the world).
My work as an intern had several areas of focus:
- building out the monitoring stack that ships with Sourcegraph
- improving the process for creating Sourcegraph releases to on-premise deployments with new capabilities
- experimenting with changes to the pipelines that help us roll out Sourcegraph changes to the various deployments we manage ourselves
A brief hiatus after my internship, I returned to Sourcegraph full-time.
# Monitoring at Sourcegraph
During my time at Sourcegraph, a major part of my focus has been on expanding the capabilities of Sourcegraph’s built-in monitoring stack and improving the experience for administrators of Sourcegraph deployments, Sourcegraph engineers, and Sourcegraph support.
- I created a new sidecar service to ship with the Sourcegraph Prometheus image, which I wrote a bit about in this blog post. This service enabled me to build:
- alerting capabilities and configuration directly within Sourcegraph, which now powers all alerting needs (routing, paging, and more) at Sourcegraph and completely replaced our old alerting infrastructure
- the ability to include recent alerts data in bug reports and render service status within the Sourcegraph app

- I built features for and refactored the Sourcegraph monitoring generator, which generates the Grafana dashboards, Prometheus rules and alerts definitions, documentation, and more that ship with Sourcegraph from a custom monitoring specification that teams use to declare monitoring relevant to their services. Some changes include:
- team ownership of alerts, which is part of what drives our alerting infrastructure and also guides support request routing.
- new API design for customising graph panels within our monitoring specification
- generated dashboard overlays for alert events and version changes
- driving a cross-team discussion to overhaul the principles that drive our work on this tooling to help guide the future of monitoring at Sourcegraph
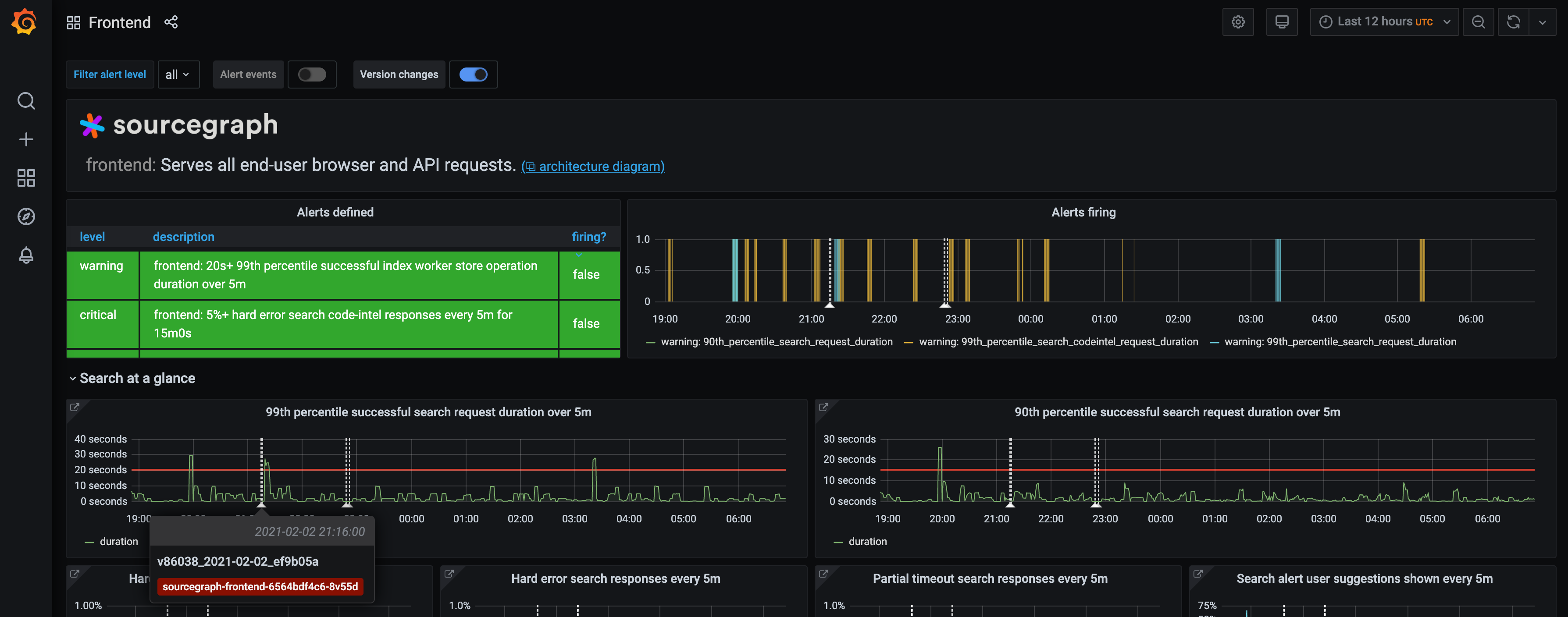
I also made a wide range of other improvements such as:
- Shipping cAdvisor with Sourcegraph, which now serves container metrics for our standardised dashboards across deployment types
- Update dashboards to scale with deployment sizes
# Sourcegraph Releases
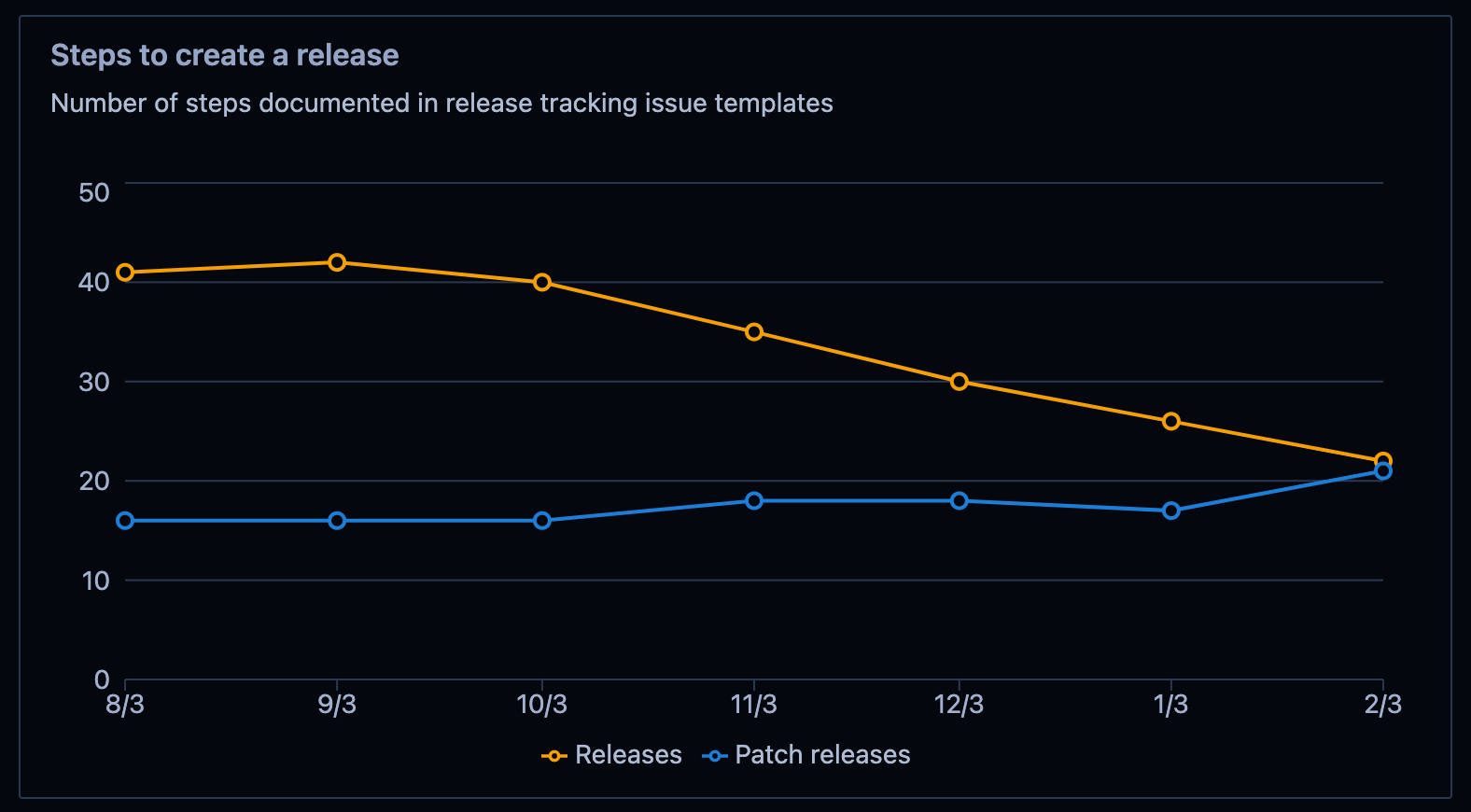
Previously, creating Sourcegraph releases was a lengthy, complex process that involved a large number of manual steps that would frequently delay our monthly releases.
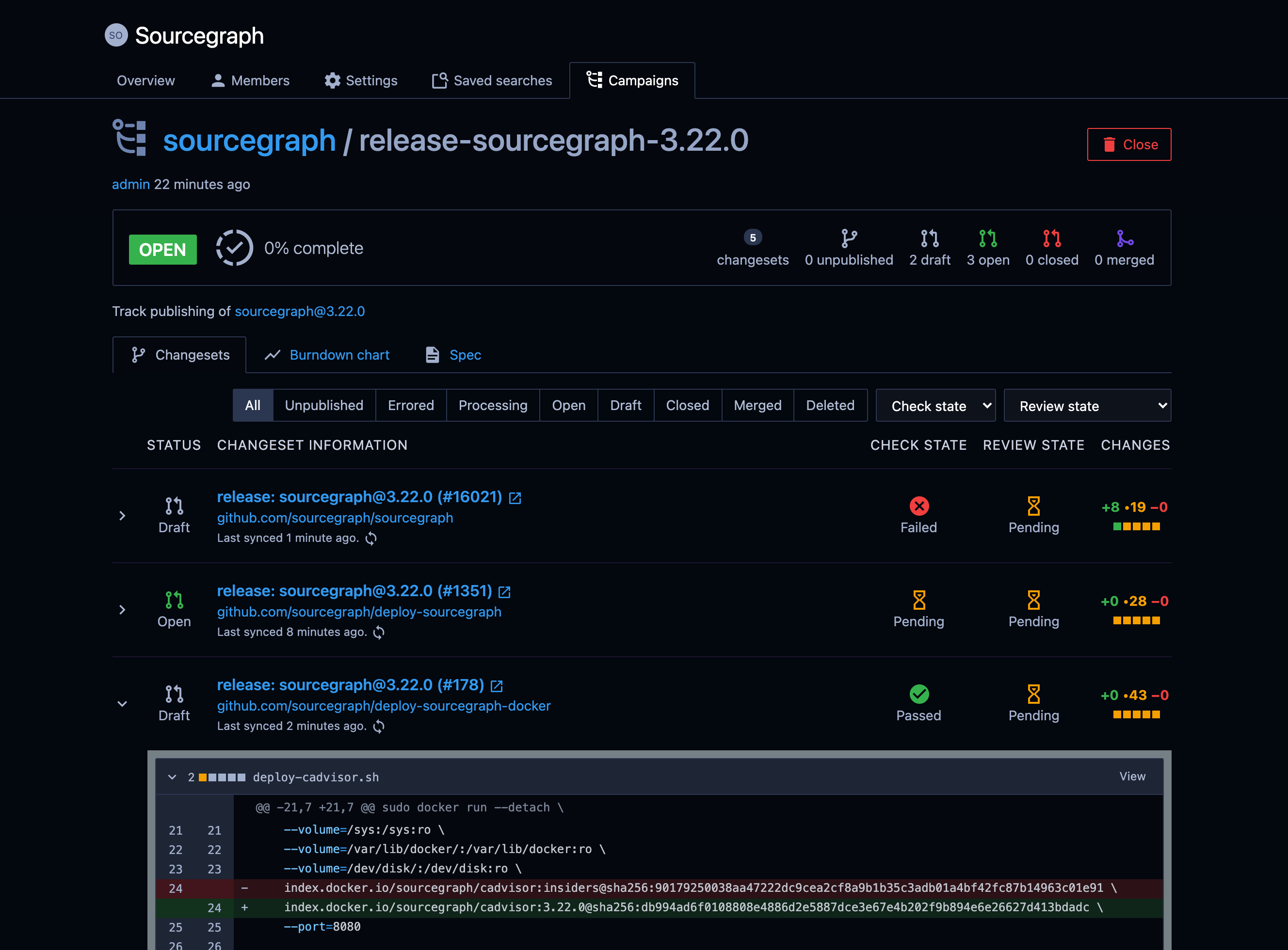
- I made extensive improvements to the Sourcegraph release tool, which handles automation of release tasks such as generating multi-repository changes, creating tags, setting up tracking issues, adding calendar events, making announcements, and more.
- New automated changes and consolidated features as part of work to reduce the number of steps to create a release
- Multi-repository changeset tracking
- Extensive refactors to improve the tool’s extensibility and reliability
- Overall, helped reduce time to cut a release from several days to just a few hours
- Improved our integration and regression testing suite by introducing the capability to directly leverage candidate images in tests, generalising test setup tooling, and migrating our automated upgrade tests to ensure compatibility
- Work on automated end-to-end testing by the Distribution team also contributed to the removal of many release steps
- The use of shared per-build candidate images is now the standard way to run integration tests, saving a lot of build time previously spent building images for each individual test
The long-term vision of this work is to enable releases to be handled by any engineer at Sourcegraph, as seamlessly and painlessly as possible, improving the pace at which we can confidently ship releases to our customers.
# Deployment Pipelines
Sourcegraph maintains a variety of Sourcegraph instances in addition to Sourcegraph Cloud. Deployment at Sourcegraph generally consists of two distinct steps:
- Building and publishing images
- Propagating published images
You can read more about this in the handbook page about instances.
I worked on making adjustments to our build and publish pipelines, such as enabling direct integration testing of candidate images and making it easier to build tooling that interacts with our images.
Deployment methodology varies from instance to instance, but when I first joined Sourcegraph we did not have any instance that was kept closely up to date synchronously with both the state of our monorepo, sourcegraph/sourcegraph, and the state of our primary method of distributing Sourcegraph, sourcegraph/deploy-sourcegraph. To amend this, I built a trigger-based pipeline that would keep deploy-sourcegraph in sync with the latest images, and immediately propagate changes in deploy-sourcegraph to an internal dogfood instance.
I also developed tooling to automate the upgrades of our managed Sourcegraph instances offering. The tooling performs Terraform rewrites, configuration updates, and more - a previously a very manual process - greatly reducing the time it takes to conduct an upgrade, and minimising the possibility of mistakes. This tooling has enabled the team to operate increasing numbers of managed instances with minimal overhead.