IPFS private network node orchestration
building Nexus, an orchestrator for operating IPFS private networks
- 31 minsRTrade Technologies wanted to explore offering a service that would provide a set of Interplanetary Filesystem (IPFS) nodes, hosted on our end, that customers can use to bootstrap their private networks - groups of IPFS nodes that only talk to each other.
These “private networks” a bit of a underdocumented feature (a quick search for “ipfs private networks” only surfaces blog posts from individuals about how to manually deploy such a network), and it kind of goes against the whole “open filesystem” concept of IPFS. That said, it seemed like it had its use cases - for example, a business could leverage a private network that used RTrade-hosted nodes as backup nodes of sorts.
So I began work (from scratch) on Nexus, an open-source service that handles on-demand deployment, resource management, metadata persistence, and fine-grained access control for arbitrary private IPFS networks running within Docker containers on RTrade infrastructure. This post is a very brief run over some of the high-level components and work that went into the project, with links to implementation details and whatnot:
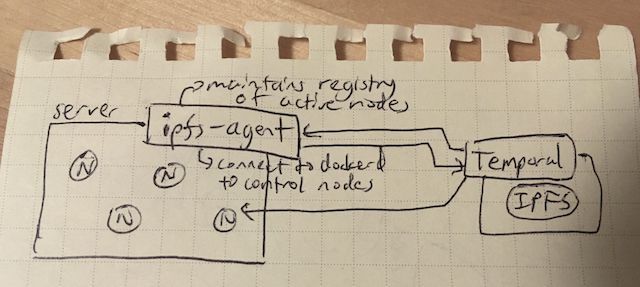
# Deploying Nodes
Deploying nodes within containers was the most obvious choice - the tech is kind of designed for situations like this, and I’ve had some experience working directly with the Docker API through my work on Inertia.
This functionality is neatly encapsualted in package Nexus/ipfs within an interface, ipfs.NodeClient, which exposes some faily self-explanatory C.R.U.D. functions to manipulate nodes directly:
type NodeClient interface {
Nodes(ctx context.Context) (nodes []*NodeInfo, err error)
CreateNode(ctx context.Context, n *NodeInfo, opts NodeOpts) (err error)
UpdateNode(ctx context.Context, n *NodeInfo) (err error)
StopNode(ctx context.Context, n *NodeInfo) (err error)
RemoveNode(ctx context.Context, network string) (err error)
NodeStats(ctx context.Context, n *NodeInfo) (stats NodeStats, err error)
Watch(ctx context.Context) (<-chan Event, <-chan error)
}
The intention of this API is purely to handle the “how” of node deployment, and not to handle the business logic that goes on to determine the when and where of deployment. Structures like NodeInfo and NodeOpts expose node configuration that can be used by upper layers:
type NodeInfo struct {
NetworkID string `json:"network_id"`
JobID string `json:"job_id"`
Ports NodePorts `json:"ports"`
Resources NodeResources `json:"resources"`
// Metadata set by node client:
// DockerID is the ID of the node's Docker container
DockerID string `json:"docker_id"`
// ContainerName is the name of the node's Docker container
ContainerName string `json:"container_id"`
// DataDir is the path to the directory holding all data relevant to this
// IPFS node
DataDir string `json:"data_dir"`
// BootstrapPeers lists the peers this node was bootstrapped onto upon init
BootstrapPeers []string `json:"bootstrap_peers"`
}
The node creation process goes roughly as follows:
-
Initialise node assets on the filesystem - most notably this includes:
- writing the given “swarm key” (used for identifying a private network) to disk for the node
- generating an entrypoint script that caps resources as required
-
Setting up configuration, creating the container, and getting the container running - this part primarily imitates your standard
docker container create, etc. commands in*docker/client.Client, edited for brevity:
resp, err := c.d.ContainerCreate(ctx, containerConfig, containerHostConfig, nil, n.ContainerName)
if err != nil { /* ... */ }
l.Infow("container created", "build.duration", time.Since(start), "container.id", resp.ID)
if err := c.d.ContainerStart(ctx, n.DockerID, types.ContainerStartOptions{}); err != nil {
go c.d.ContainerRemove(ctx, n.ContainerName, types.ContainerRemoveOptions{Force: true})
return fmt.Errorf("failed to start ipfs node: %s", err.Error())
}
// waitForNode scans container output for readiness indicator, and errors on
// context expiry. See https://github.com/RTradeLtd/Nexus/blob/master/ipfs/client_utils.go#L22:18
if err := c.waitForNode(ctx, n.DockerID); err != nil { /* ... */ }
// run post-startup commands in the container (in this case, bootstrap peers)
// containerExec is a wrapper around ContainerExecCreate and ContainerExecStart
// See https://github.com/RTradeLtd/Nexus/blob/master/ipfs/client_utils.go#L141:18
c.containerExec(ctx, dockerID, []string{"ipfs", "bootstrap", "rm", "--all"})
c.containerExec(ctx, dockerID, append([]string{"ipfs", "bootstrap", "add"}, peers...))
- Once the node daemon is ready, bootstrap the node against existing peers if any peers are configured
Some node configuration is embedded into the container metadata, which makes it possible to recover the configuration from a running container. This allows the orchestrator to bootstrap itself after a restart, and is used by NodeClient::Watch() to log and act upon node events (for example, if a node crashes).
This interface neatly abstracts away the gnarly work makes it very easy to generate a mock for testing, which I will talk about later in this article. This particular example is from TestOrchestrator_NetworkUp, edited for brevity:
client := &mock.FakeNodeClient{}
o := &Orchestrator{
Registry: registry.New(l, tt.fields.regPorts),
client: client,
address: "127.0.0.1",
}
if tt.createErr {
client.CreateNodeReturns(errors.New("oh no"))
}
if _, err := o.NetworkUp(context.Background(), tt.args.network); (err != nil) != tt.wantErr {
t.Errorf("Orchestrator.NetworkUp() error = %v, wantErr %v", err, tt.wantErr)
}
# Orchestrating Nodes
The core part of Nexus is the predictably named orchestrator.Orchestrator, which exposes an interface very similar to that of ipfs.NodeClient, except for more high-level “networks”. A bit more work goes on the the orchestrator - for example, since ipfs.NodeClient does very straight-forward node creation given a set of parameters, port allocation and database management are left to the orchestrator. Managed in memory are two registries that cache the state of the IPFS networks deployed on the server to help it do this:
-
registry.Registry, which basically provides cached information about active containers for faster access than constantly queryingdockerd. It is treated as the live state, and is particularly important for access control, which needs to query container data very often (more on that later). -
network.Registry, which accepts a set of ports from configuration that the orchestrator can allocate, and when requested scans ports to provide an available. This is used several times during node creation - each node requires a few ports available to expose APIs and do things.
The orchestrator also has access to the RTrade databasse, which do all the normal making-sure-a-customer-has-sufficient-currency work and so on, and syncs the state of deployed networks back to the database. It also does things like bootstrap networks on startup that should be online that aren’t. Overall it is fairly straight-forward - most of the work is encapsulated within other components, particularly ipfs.NodeClient.
The functionality of the orchestrator is exposed by a gRPC API, which I talk about a bit more in Exposing an API.
# Access Control
IPFS nodes expose a set of endpoints on different ports: one for its API, one for its gateway, and one for swarm communication. We wanted to be able to expose these to customers without having to either provide a set of permanent port number on our domain (for example, nexus.temporal.cloud:1234) or asking them to constantly update the ports they connect to. We also wanted to be able to provide the ability to restrict ports to those with valid RTrade authentication - particularly the API, which exposes some potentially damaging functionality.
We eventually decided to aim for the ability to provide customers with a subdomain of temporal.cloud with a scheme like {network_name}.{feature}.{domain} (for example, my-network.api.nexus.temporal.cloud) and have Nexus automatically delegate requests to the appropriate port (where a node from the appropriate network would be listening for requests).
To do this, I created the (again) predictably named delegator.Engine over the course of two pull requests (#13, where I implemented a path-based version of the scheme, and #22, where I finally got the subdomain-based routing working) to act as a server for delegating requests based on the URL scheme we decided on.
The interface exposed by delegator.Engine is not particularly self-explanatory, since most of its functions are designed to work as go-chi/chi middleware.
The subdomain routing scheme starts with a chi hostrouter, which I had to fork to implement wildcard matching (sadly, it seems no one is keeping an eye on the repository, and the PR has gone unnoticed). Here’s a snippet from delegator.Engine::Run():
// ...
hr := hostrouter.New()
hr.Map("*.api."+e.domain, chi.NewRouter().Route("/", func(r chi.Router) {
r.Use(e.NetworkAndFeatureSubdomainContext)
r.HandleFunc("/*", e.Redirect)
}))
hr.Map("*.gateway."+e.domain, chi.NewRouter().Route("/", func(r chi.Router) {
r.Use(e.NetworkAndFeatureSubdomainContext)
r.HandleFunc("/*", e.Redirect)
}))
// ...
What this does is listen for all requests to *.api.nexus.temporal.cloud, for example, and route them through an unpleasantly named context injector (delegator.Engine::e.NetworkAndFeatureSubdomainContext) and feed requests to the redirector (delegator.Engine::Redirect). The former more or less does as its name describes: it parses the network (a name) and feature (api, gateway, etc.), retrieves metadata about the network from the previously mentioned node registry, and injects it into the request’s context.Context. This is a inexpensive operation, since the node registry is implemented as an in-memory cache. Subsequent handlers can then use the injected metadata by retrieving it from the context to do whatever they need to do.
func (e *Engine) NetworkAndFeatureSubdomainContext(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// ...
next.ServeHTTP(w, r.WithContext(
context.WithValue(
context.WithValue(r.Context(),
keyFeature, // context key
feature), // value
keyNetwork, // context key
&n), // value
))
})
}
For most request, the subsequent handler is the redirect handler:
func (e *Engine) Redirect(w http.ResponseWriter, r *http.Request) {
// retrieve network
n, ok := r.Context().Value(keyNetwork).(*ipfs.NodeInfo)
if !ok || n == nil {
res.R(w, r, res.Err(http.StatusText(422), 422))
return
}
// retrieve requested feature
feature, ok := r.Context().Value(keyFeature).(string)
if feature == "" {
res.R(w, r, res.ErrBadRequest("no feature provided"))
return
}
// ... do things
}
I’ll just take a quick moment to plug my library, res, which provides the nice (I think) shorthands for the RESTful responses you see in the snippet above.
The rest of the code handles each feature case by case, with some notable cases highlighted in this snippet:
-
apirequests are restricted with authentication using the same JWT we use for other RTrade services -
gatewayaccess can be disabled via configuration
switch feature {
// ...
case "api":
// IPFS network API access requires an authorized user
user, err := getUserFromJWT(r, e.keyLookup, e.timeFunc)
if err != nil {
res.R(w, r, res.ErrUnauthorized(err.Error()))
return
}
entry, err := e.networks.GetNetworkByName(n.NetworkID)
if err != nil {
http.Error(w, "failed to find network", http.StatusNotFound)
return
}
var found = false
for _, authorized := range entry.Users {
if user == authorized {
found = true
}
}
// ...
port = n.Ports.API
case "gateway":
// Gateway is only open if configured as such
if entry, err := e.networks.GetNetworkByName(n.NetworkID); err != nil {
res.R(w, r, res.ErrNotFound("failed to find network"))
return
} else if !entry.GatewayPublic {
res.R(w, r, res.ErrNotFound("failed to find network gateway"))
return
}
port = n.Ports.Gateway
}
At the end of each handling, an appropriate target port is set, which is then used to generate a reverse proxy for this request, edited for brevity:
// set up target
var (
address = fmt.Sprintf("%s:%s", network.Private, port)
target = fmt.Sprintf("%s%s%s", protocol, address, r.RequestURI)
protocol = "http://"
)
if r.URL.Scheme != "" {
protocol = r.URL.Scheme + "://"
}
url, err := url.Parse(target)
// ...
// set up forwarder, retrieving from cache if available, otherwise set up new
var proxy *httputil.ReverseProxy
if proxy = e.cache.Get(fmt.Sprintf("%s-%s", n.NetworkID, feature)); proxy == nil {
proxy = newProxy(feature, url, e.l, e.direct)
e.cache.Cache(fmt.Sprintf("%s-%s", n.NetworkID, feature), proxy)
}
// serve proxy request
proxy.ServeHTTP(w, r)
In classic Go-batteries-included fashion, most of the work is done by a nice utility straight from the standard library: httputil.ReverseProxy - all I really had to do was implement a Director to set the parameters such that every request will be delivered to the correct node’s correct doorstep:
func newProxy(feature string, target *url.URL, l *zap.SugaredLogger, direct bool) *httputil.ReverseProxy {
return &httputil.ReverseProxy{
Director: func(req *http.Request) {
// if set up as an indirect proxy, we need to remove delgator-specific
// leading elements, e.g. /networks/test_network/api, from the path and
// accommodate for specific cases
if !direct {
switch feature {
case "api":
req.URL.Path = "/api" + stripLeadingSegments(req.URL.Path)
default:
req.URL.Path = stripLeadingSegments(req.URL.Path)
}
}
// set other URL properties
req.URL.Scheme = target.Scheme
req.URL.Host = target.Host
},
}
}
These reverse proxies are cached so that the delegator doesn’t have to construct them all the time, with evictions based on expiry so that outdated proxies don’t persist for too long.
# Exposing an API
Most of RTrade’s services expose functionality via gRPC (a remote procedure call framework), with service definitions and generated Go stubs housed in a standalone repository, RTradeLtd/grpc - so it made sense that Nexus would have its features available via gRPC as well. Check out the generated stubs here, but the interface is pretty simple (full spec):
package nexus;
service Service {
rpc Ping(Empty) returns (Empty) {};
rpc StartNetwork(NetworkRequest) returns (StartNetworkResponse) {};
rpc UpdateNetwork(NetworkRequest) returns (Empty) {};
rpc StopNetwork(NetworkRequest) returns (Empty) {};
rpc RemoveNetwork(NetworkRequest) returns (Empty) {};
rpc NetworkStats(NetworkRequest) returns (NetworkStatusReponse) {};
rpc NetworkDiagnostics(NetworkRequest) returns (NetworkDiagnosticsResponse) {};
}
Generated stubs save a lot of time in implementation - interfaces in front of the generated implementation allow quick and easy mocking (see Testing), and takes away the tedium of writing API calls from scratch. In particular, the generated server implementation makes it very easy to implement the gRPC spec. In this case, the spec is implemented by a small service, the Nexus daemon.Daemon, and its primary functionality is to get the gRPC server up and running with the appropriate configuration, middleware, and monitoring hooks and translating the gRPC requests to commands for the orchestrator. Two simple commands can deploy a daemon locally with most configuration set to reasonable defaults:
$> nexus init
$> nexus daemon
To facilitate testing, I wrote a small library, bobheadxi/ctl, that uses reflection on the Nexus gRPC client (or any arbitrary client) to translate string inputs into gRPC calls, with the goal of being embedded in a CLI:
import "github.com/bobheadxi/ctl"
func main() {
// instantiate your gRPC client
c, _ := client.New( /* ... */ )
// create a controller
controller, _ := ctl.New(c)
// execute command
out, _ := controller.Exec(os.Args[0:], os.Stdout)
}
In the Nexus CLI, this library is embedded under the nexus ctl command. Using it on a local Nexus instance looks like:
$> nexus ctl help
$> nexus -dev ctl StartNetwork Network=test-network
$> nexus -dev ctl NetworkStats Network=test-network
$> nexus -dev ctl StopNetwork Network=test-network
I introduced this feature very early on, and it came in useful as Nexus’s capabilities grew, making it easy to demonstrate new features:
nexus ctl command to demonstrate MVP functionality - from #6.I eventually added a couple of the nexus ctl commands to our Makefile as well for convenience:
.PHONY: start-network
start-network: build
./nexus $(TESTFLAGS) ctl --pretty StartNetwork Network=$(NETWORK)
nexus ctl commands (from make) to demonstrate a new feature - from #13.# Testing
Testing, while sometimes tedious, is a great way to have confidence in the functionality of a codebase, give you a tighter iterate -> verify -> iterate loop, and gives you the ability to make significant refactors as project requirements change while verifying core features still workked as expected. A halfway-decent measure of this is code coverage!
![]()

Tests mostly fall in one of two categories (in my mind at least): unit tests that run without any setup and involve no non-library dependencies, and integration tests that involve external dependencies.
Integration tests spanning my external dependencies are usually the first tests I write in a project - they typically take very little code to set up (since integration environment is something I set up early on anyway so I can run my applications locally), and I only test a few high-level functions, so I don’t have to constantly update my tests for changes in API or function names (which I find myself doing often when I write unit tests too early). They also serve to familiarise me with the services or tooling I will be depending on.
For the integration environment, the only real dependencies are Docker and a Postgres database. The former I just assume is already running, and the latter I set up using RTrade’s centralised test environment repository (which I made) - this repository is typically included as a git submodule in RTrade projects.
COMPOSECOMMAND=env docker-compose -f testenv/docker-compose.yml
.PHONY: testenv
testenv:
$(COMPOSECOMMAND) up -d postgres
Writing an integration test then involves just making sure I do the appropriate setup and teardown throughout a test run. Using ipfs.NodeClient tests as an example (I do recommend giving the source a quick skim, since there’s a lot going on) I ended up just testing most of my CRUD operations in one go (since that’s basically already setup and teardown), edited for brevity:
// grab temp space for assets, set up a test logger, initialise client
c, err := newTestClient()
if err != nil { /* ... */ }
// test watcher, and make sure the correct number of events happened
var eventCount, shouldGetEvents int
watchCtx, cancelWatch := context.WithCancel(context.Background())
go func() {
events, errs := c.Watch(watchCtx)
for {
select {
case err := <-errs:
if err != nil { /* ... */ }
case event := <-events:
eventCount++
}
}
}()
// table of test cases
type args struct {
n *NodeInfo
opts NodeOpts
}
tests := []struct {
name string
args args
wantErr bool
}{
{"invalid config", args{ /* ... */ }, true},
{"new node", args{ /* ... */ }, false},
{"with bootstrap", args{ /* ... */ }, false},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
ctx := context.Background()
// create node
if err := c.CreateNode(ctx, tt.args.n, tt.args.opts); (err != nil) != tt.wantErr {
t.Errorf("client.CreateNode() error = %v, wantErr %v", err, tt.wantErr)
return
}
// handle want-error cases differently
if tt.wantErr { /* ... */ }
// clean up afterwards
defer func() {
c.StopNode(ctx, tt.args.n)
c.RemoveNode(ctx, tt.args.n.NetworkID)
}()
// check that container is up, watcher should receive an event. do a crude
// wait to give the node time to start up
shouldGetEvents++
time.Sleep(1 * time.Second)
n, err := c.Nodes(ctx)
if err != nil {
t.Error(err.Error())
return
}
for _, node := range n {
if node.DockerID == tt.args.n.DockerID {
goto FOUND
}
}
t.Errorf("could not find container %s", tt.args.n.DockerID)
return
FOUND:
// should receive a cleanup event - use this to verify
shouldGetEvents++
// get node stats
_, err := c.NodeStats(ctx, tt.args.n)
if err != nil {
t.Error(err.Error())
return
}
// stop node
c.StopNode(ctx, tt.args.n)
})
}
cancelWatch()
// verify events occurred
if shouldGetEvents != eventCount {
t.Errorf("expected %d events, got %d", shouldGetEvents, eventCount)
}
For unit tests, the abstraction around the highly involved work done in ipfs.NodeClient can easily be mocked out using my generator of choice, maxbrunsfeld/counterfeiter. In Go, mocking tyically takes the form of taking an interface, and generating and implementation for the interface that behaves as configured. This works because of how interfaces are implemented implicitly.
To generate an implementation, we just point counterfeiter at the appropriate interface:
counterfeiter -o ./ipfs/mock/ipfs.mock.go ./ipfs/ipfs.go NodeClient
This gives us a struct with a huge variety of useful functions that help define behaviours per test run. For example, to test orchestrator.Orchestrator, we want to stub out ipfs.NodeClient to make sure we only test the orchestrator’s functionality:
type fields struct {
regPorts config.Ports
}
type args struct {
network string
}
tests := []struct {
name string
fields fields
args args
createErr bool
wantErr bool
}{
{"invalid network name", fields{config.Ports{}}, args{""}, false, true},
{"nonexistent network", fields{config.Ports{}}, args{"asdf"}, false, true},
{"unable to register network", fields{config.Ports{}}, args{"test-network-1"}, false, true},
{"instantiate node with error", fields{config.New().Ports}, args{"test-network-1"}, true, true},
{"success", fields{config.New().Ports}, args{"test-network-1"}, false, false},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
l, _ := log.NewTestLogger()
client := &mock.FakeNodeClient{} // the mock we generated!
o := &Orchestrator{
Registry: registry.New(l, tt.fields.regPorts),
l: l,
nm: nm,
client: client,
address: "127.0.0.1",
}
// set up how the fake client works under specific conditions
if tt.createErr {
client.CreateNodeReturns(errors.New("oh no"))
}
if _, err := o.NetworkUp(context.Background(), tt.args.network); (err != nil) != tt.wantErr {
t.Errorf("Orchestrator.NetworkUp() error = %v, wantErr %v", err, tt.wantErr)
}
})
}
Through a combination of generated mocks, and effective abstraction around external dependencies, you can get pretty testing and good code coverage from both integration and unit tests that can cover pretty much any edge case you want even in a statically typed language like Go. It’s pretty straight-forward to set up, is safely typed, and does not need to involve the “magic” of dependency injection frameworks (which I’ve previously used in Java). I like to compare good tests to having a good foundation to work and pivot on - try to pivot while running on sand, and you fall on your face as your features blow up around you. ![]()
That’s all I had to share in this post (which got a bit lengthier than I expected) - hopefully somebody finds this useful!