Domain-Specific Search Engine
Domain-Specific Search Engine
![]()
![]()
![]()



Ever wanted to find something specific about the University of British Columbia - such as your course site - only to find yourself wading through a hundred irrelevant Google results? Sleuth is a service that allows anyone to search up UBC-relevant content gathered by our own web crawlers and indexed by our own database built on Solr.
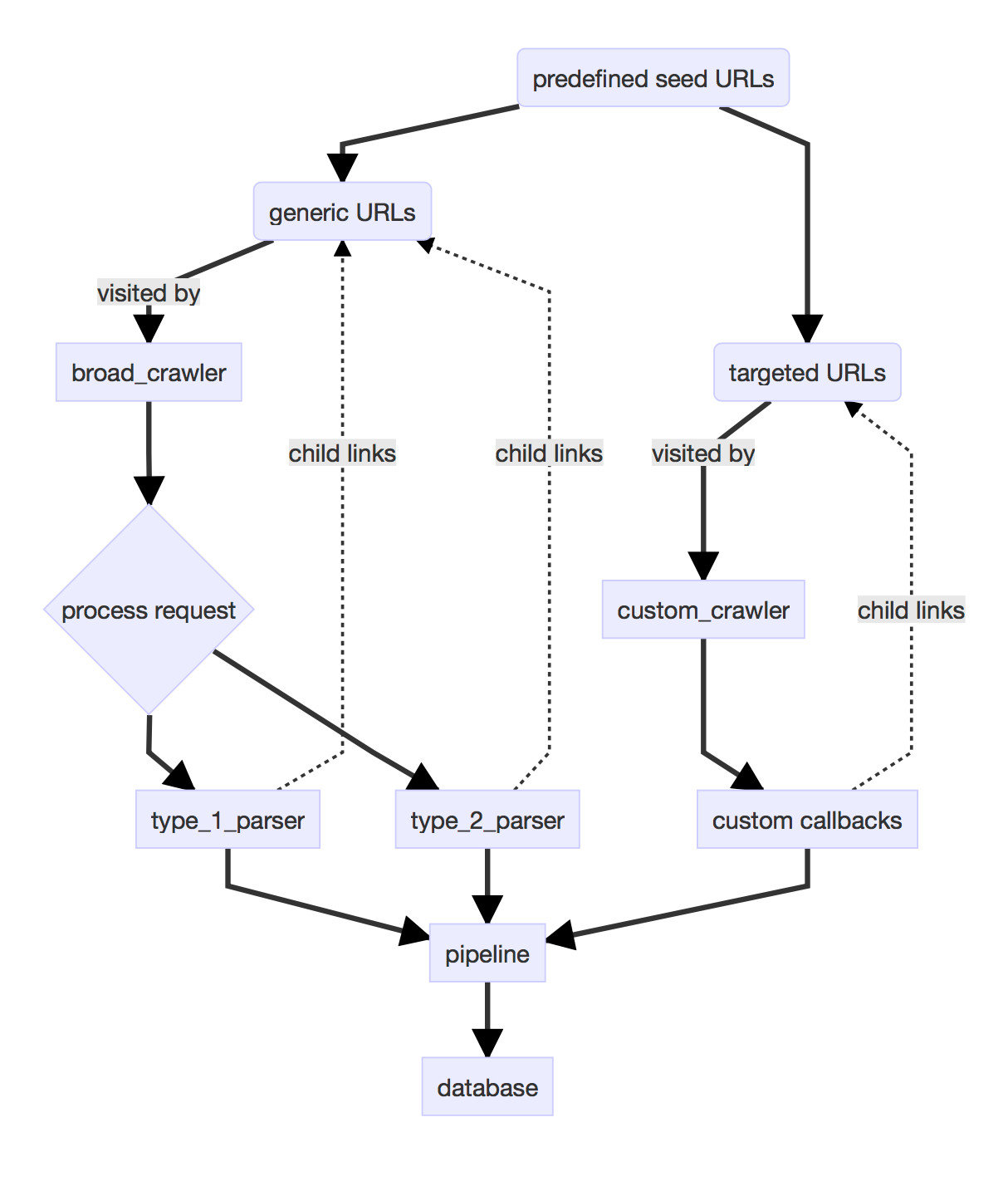
Built by a tiny team of 2, the Sleuth project features two major components - the Sleuth backend and server, and the Sleuth frontend website, both of which can be easily deployed through Docker using a simple docker-compose up command. The backend features:
- comprehensive and well-documented endpoints built on Django that expose the Sleuth search service through RESTful APIs and serve relevant errors and status codes thanks to effective exception handling within the codebase
- a robust and modular architecture featuring custom internal query-building modules to simplify tweaking our search parameters and weights and abstracted database component built on Apache Solr
- domain-specific broad crawlers designed to handle all sorts of web pages and content, parsing them in relevant formats through our efficient data pipeline featuring automated entry queuing (read more in my blog post!)
- relevant results using webpage links and key words determined by natural language processing libraries to connect related results and served by the Sleuth APIs
- thoroughly tested code, with over 90% coverage
The React-based Sleuth frontend features:
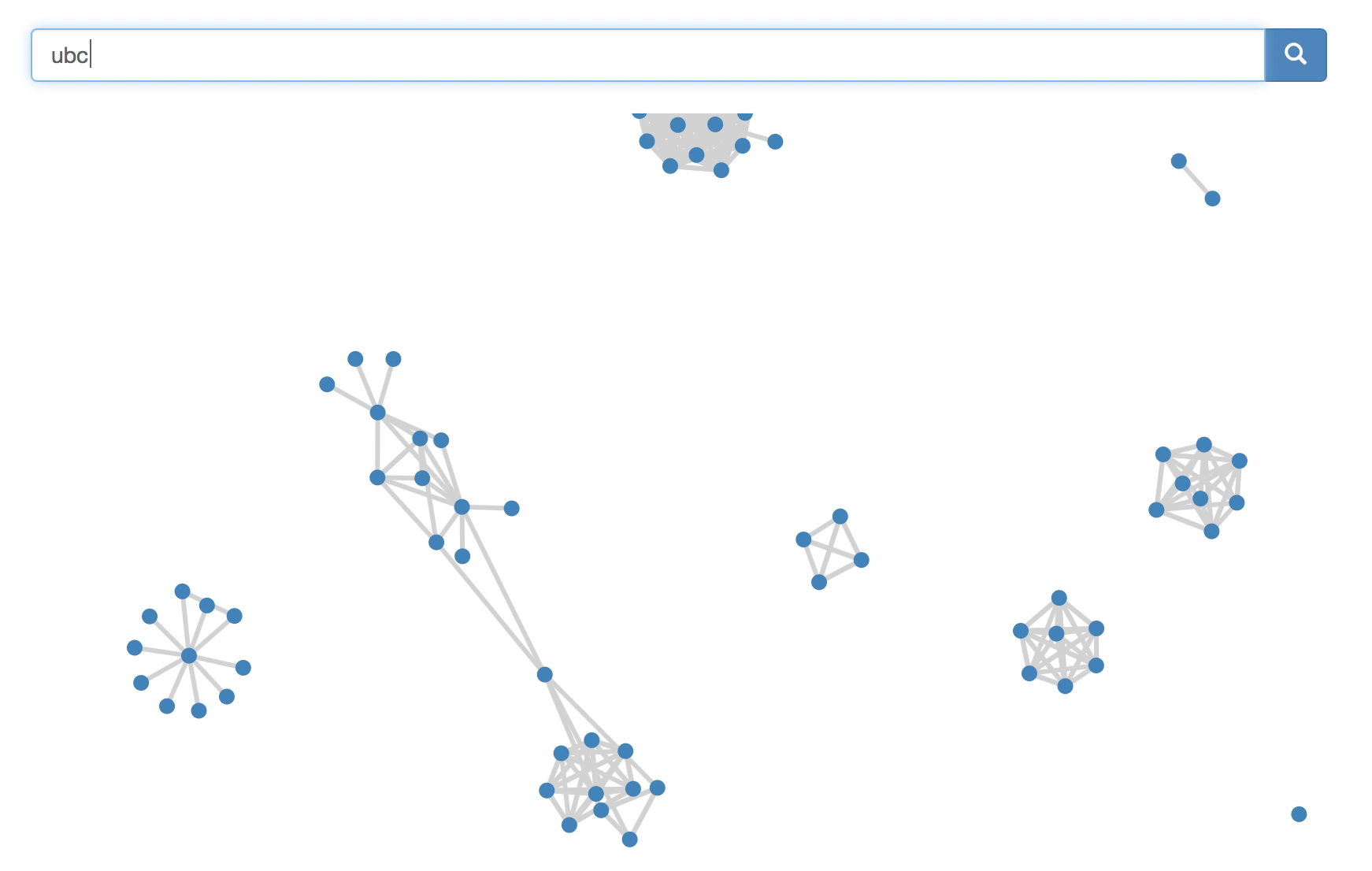
- innovative, sprawling, network-based results view to allow users to determine what results might be most relevant to them at a glance, though Sleuth also provides a more traditional list-based view for those inclined
- close integration with the Sleuth backend to display summaries of the various webpage types stored by the Sleuth crawler
More details can be found in the two Sleuth repositories!